We’re heading toward a world where AI agents manage large parts of our personal and business lives. They will make important decisions as representatives of us and manage our knowledge.
One of the core problems of our time is the increasing centralization of power: as we get increasingly powerful AI agents (and we will), it will really start to matter who controls these AI systems. If we're not careful, we may allow a small number of for-profit companies to control the power of AI agents and our access to those agents.
AI companies do not care about you
At the core, it's a question of power. When AI agents are owned and controlled by a huge company, they will eventually choose profits over you.
Imagine you’re having a medical emergency and you ask your agent which doctor you should go to. One doctor is not very good and barely certified, but they paid OpenAI $1M to advertise their services to you. Will you trust OpenAI to reject the $1M?
We cannot meaningfully change these agents, we cannot peek inside the agents’ brains to see how it made its decision, and critically, we cannot ensure that those agents are working towards our goals.
When there is a huge power asymmetry--like there is between an individual consumer and a $100 billion company--guess which goals end up getting prioritized?
AI companies will profit by exploiting us
When VCs and companies are pouring hundreds of billions of dollars into something, you have to ask yourself: are they all crazy, or do they actually see a plausible path to being able to exploit the world so much in the future that they'll be able to not only recoup that money, but make even more?
The definition of investment is to spend money now in order to make a profit later.You have to wonder: how will AI companies make so much profit that they can justify spending upwards of a trillion dollars?
The Stargate Project alone is estimated at about $500 billion dollars. If we assume that represents half of the spend over the next decade, and they wanted to 2x their investment, they would need to make about as much money as is spent by every person during the entire year in Australia (as the 15th largest country by GDP, their GDP is about $2 trillion). That's an astonishing amount of money.
It's simply not possible to make that money by taking a small fraction of the total spend--these companies are not looking to make a few percent, like an infrastructure or utility company (e.g. power companies have around a 10% margin). These companies are going to try to make a 90% margin--they want to be selling you something for $10 that costs them $1. So when you ask an AI agent to do something in the future, it's probably going to cost you $10 for the work that OpenAI spent $1 to do. That's literally their plan: to make great margins, and expand to do a huge fraction of the world's knowledge work. Now you see why VCs and companies are so excited.
But it doesn't have to be this way.
The future of AI must be open
If we can make free software and open alternatives to these closed AI systems, then these closed AI model providers won't have any real leverage or pricing power. If people are free to switch to their own open models at any time, or to run agents on whatever provider they want--including even their own local hardware--then these large companies will be forced to play the (appropriate) role of infrastructure. If they really do want to make "intelligence too cheap to meter,” then we want them making money like utilities (10% margins)--not like software businesses (90% margins).
Thankfully, open models are already a surprisingly good alternative--the latest open source GLM5.1 model has higher benchmark scores than even the best available closed models (eg, Opus 4.6 and GPT 5.4). Even other models like kimi k2.5, qwen, and deepseek are close to the best closed models on many benchmarks and tasks, despite being trained for a tiny fraction of the cost that went into training for the closed models. And open models have been improving at a rate that exceeds even the closed models (which are themselves improving quite rapidly). Unlike even a year or two ago, when Meta's LLAMA models were pretty much the only game in town, there is now great competition at the model layer to provide the best open weight models, with companies like Moonshot AI, DeepSeek AI, and Reflection all hard at work to create the next best, most useful, open models and make them freely available to the world.
These open models are already having a powerful effect on the market. In just a short time, they've turned LLM inference from a place where companies had hoped to make healthy margins to a place where even many of the closed AI companies are effectively forced to sell their models at a loss to compete.
Because of the presence of open models, there's always the option of just buying your own hardware (or renting from a variety of cloud providers all in cutthroat competition with one another) and running an open model, which puts strong downward pressure on the price of AI inference.
But the future of AI is about more than just open-weight models and inference: we need viable open alternatives for the entire stack, all of the way from pre-training to the final systems for AI agents, and for usefully coordinating those agents.
This is why I'm focused on freesoftware rather than focusing too narrowly on, say, AI models or AI agents. Certainly, AI agents and their supporting infrastructure seem like one of the next most critical places where we need compelling open alternatives (which is why we've built Mngr, and are planning to make its source available in the future). But it's more important that we create an entire, thriving ecosystem of open, free software for the entire lifecycle of training and deploying AI, lest some part of that chain become captured by a small number of for-profit companies.
One of the nice things about this effort is that it is gradual: it's not necessarily a binary outcome where either 100% of AI systems are closed or 100% are open. Rather, each little library we make, each task we make more transparent, and each new open source project contributes to making it easier to access AI technologies freely.
Collectively, our efforts towards making open and free software eventually add up to shift the overall balance from closed to open.
What an open AI ecosystem could do for us
If we can keep free and open AI software components competitive with closed alternatives across the stack or, better yet, make them unarguably better (which I think is possible!), then we invite far better futures for all of us.
Rather than a world where these AI systems are black boxes, we can have one where anyone can open them up and understand how they work (and improve them!)
Rather than a world where we pay too much for access to the critical tools and technologies of the future, we can have a competitive market that provides useful AI tools efficiently and cheaply.
Rather than a world where money and power continually accumulate to a small number of the largest companies, we can have a world where anyone is free to run AI agents to build their own ideas and bring their own visions to life, and even make a living doing so.
Instead of a world with a small number of huge data centers that pose national security and ecological risks, we can distribute AI compute processes to systems owned and controlled by each individual, and which promotes a more stable geopolitical climate.
Instead of a world with a monoculture of models, we can have a diversity of local and personal models better suited to the individuals and communities that use them.
So let's ruthlessly copy, duplicate, and commodify these closed AI systems. Let's share data and collaborate on building open systems that benefit everyone in the world rather than create a brittle world where our creativity and productivity are constrained, safe, and profitable only for the largest companies.
Sure, in these worlds, some of these initial investors might not make the huge returns they were hoping for. But the rest of us will be far better off, and it's not our responsibility to guarantee their returns for such risky investments.
We can create an explosion of diverse ways of thinking, creating, and building with software. We can create a world where our future AI tools are directly under our own personal control, and where we can spend time working on the things that we care about--without worrying about losing access to critical infrastructure because some company finds our work displeasing or unprofitable.
We can make good futures that have AI.
To do so, we need to make AI software part of the public commons, and not let it be something locked behind a private paywall.
Given the impending rise of AI agents, it makes more sense to think of intelligence as a commodity, like steel or grain.
Thinking of intelligence as a commodity is better because it is both:
A more accurate way of thinking about intelligence and
A model that is better for humanity
For the purposes of this essay, I’m defining “intelligence” as “the capacity to accomplish goals"1. This capability is becoming increasingly interchangeable and replaceable, and it is worth considering the implications of that change.
It is more accurate to think of intelligence as a commodity
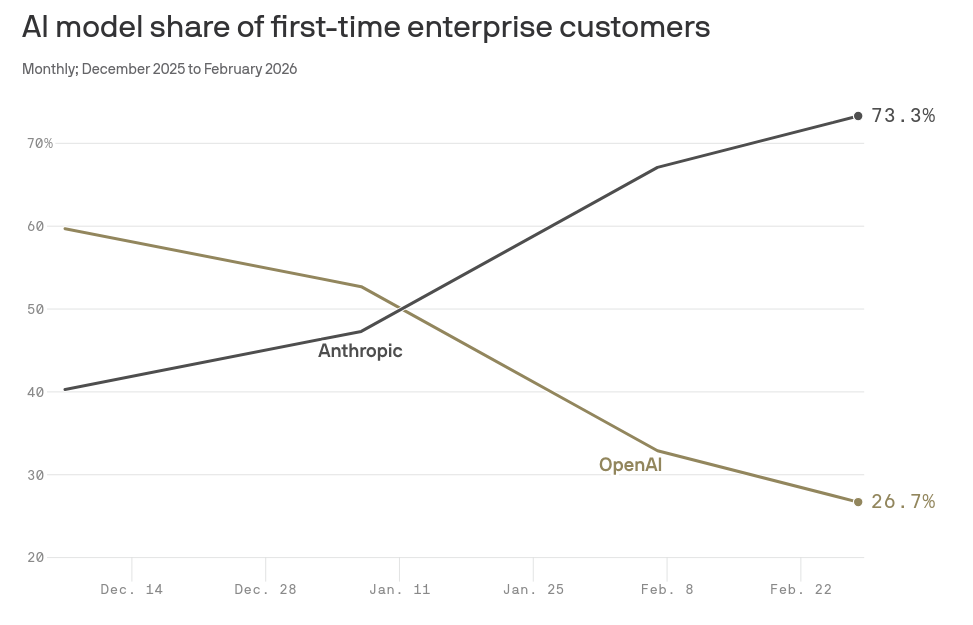
The dramatic shift from OpenAI usage to Anthropic usage over the past few months is a pretty clear indication that, at least today, the preferred model provider can change very quickly:
Wikipedia defines a commodity as a case where "the market treats instances of the good as equivalent... with no regard to who produced them”. The fact that it is so easy for users to switch, and that each provider’s capabilities are advancing at roughly the same rate, both indicate that AI inference today is a commodity.
As users, we want a system that answers our question correctly and that generates useful text. Most people don't care about precisely which logo was associated with the GPUs that produced the output.
Thinking about intelligence as a commodity has some fascinating implications for the future:
We should expect the price to fall dramatically as production becomes more standardized and efficient. This is what typically happens for commodities (see e.g. Wright’s Law)
We should start thinking in terms of "how much" intelligence we need for a given task, and how we might quantify the "mental effort" (i.e., compute) required to accomplish a particular goal.
We should plan for a world where we can simply ‘buy’ more intelligence when it is needed, rather than going through a lengthy process of vetting and hiring to get any non-trivial job done.
We can better separate situations where we just need raw intelligence (pure "goal accomplishing mental effort") from situations where we also need properties that currently cannot be as easily supplied by AI systems today (properties like intuition, judgment, taste, creativity, and accountability).
We should expect the returns on capital invested to be fairly modest. Commodities like steel or corn (and now intelligence), when faced with competition, will drive profits toward near-zero over time.
We're likely to see AI agents become increasingly capable of doing most of today's knowledge work, and likely over a fairly short time period (the next ~decade).
If current trends of improvement in AI capabilities hold for even a few more years, we will have AI systems capable of doing a large fraction of the mental labor performed today. We will have systems capable of answering questions, performing basic online research, gathering information, and assembling it into both documents and decisions.
This isn’t to say that there is only "one type of intelligence" that will excel at everything. But as intelligence becomes more widely available, we can increasingly tailor it to specific goals or domains. In that sense, some forms of intelligence may start to resemble a commodity like steel: it comes in many different forms (bars, rods, ore, etc.), that can be shaped and applied for different uses.
AI system performance largely boils down to the quantity and quality of its components: how many GPUs, parameters, and training data of what level of quality was used in its construction. Some day soon, the quality of an AI system may be considered more like the purity of steel.
But perhaps one of the most important implications is how it changes our collective relationship to intelligence. That brings us to the normative claim.
Treating intelligence as a commodity will be better for humanity
Not only does it seem like intelligence is likely to become a commodity, this is also a belief worth promoting and spreading.
There are several reasons for this.
First, if we view intelligence as a commodity, then AI companies are relegated to being providers of a basic service. If they're just making an interchangeable commodity, then they're welcome to compete on driving down the price for that, and we ought to encourage abstraction over any one provider.
In the same way I don’t want to be stuck with Comcast as my only option for internet, I don’t want to rely on a single AI company for my intelligence. We want to play these companies against each other, to avoid lock-in, and treat them like the commodities that they are. Over time, this will drive the price down as they are forced to compete by making their models ever more efficient and capable. This is capitalism at its best, but only if we can avoid engaging with AI inference as anything but a commodity.
This naturally leads to asking more of the right questions, like "what grade [how good] is this intelligence" and "how likely is this AI system to actually accomplish my goal [to a given level of quality]?" One of the most important aspects of a commodity is that it is of a known, well-understood level of quality.
Just as steel purity is graded by precise specifications (food-safe, tolerance for defect, etc.), so too should there be defined levels of intelligence.We want to measure and quantify these systems more precisely so we can ensure that we receive the level of quality we expect. This means spending more time and effort on evaluations, and on deeply understanding the flaws and defects in these systems, and precisely how often they occur. It's not magic, any more than testing the strength of a steel beam.
Another benefit of viewing intelligence as a commodity is that it is quite equalizing for most of us. In a world where intelligence is something that can be tapped into and applied to any problem as easily as turning on a faucet, there's no longer an implicit hierarchy in society where "experts" get to tell the rest of us how the world works or what to think.
When anyone can spin up an AI PhD to investigate a question, we will have a greater capacity to investigate the questions we're curious and passionate about. When we know the quality level of that AI PhD--i.e., how likely it is to create a correct, truthful response for a given question--then we can start to determine how much we trust those answers. There will still be inequality, but less than before--when everyone has access to the same level of intelligence, then anyone can use AI to accomplish the goals they care about.
There are good reasons to believe, rationally, that intelligence is most accurately viewed as a commodity. But, more importantly, the world will be better if act like intelligence is a commodity. Rather than elevating these AI labs and being so impressed at their every new release, we should start accepting that this is just a new type of steel that enables us to build new types of structures.
Once we accept that AI companies are approximately as interesting as steel manufacturers, perhaps then we can start talking about the more interesting questions: given this new type of material, what do we want to build? Do we want to make multi-story parking lots, or do we want to build cathedrals?
The best definition I've encountered for intelligence is from Shane Legg and Marcus Hutter in their paper "Universal Intelligence: A Definition of Machine Intelligence". They define intelligence as: "an agent’s ability to achieve goals in a wide range of environments." ↩︎
Tomorrow's software engineers won't write code, they'll grow it.
As AI systems become capable of autonomous development, our role as software engineers will shift from construction to cultivation. We’ll continually plant ideas, prune complexity, and shape living systems that evolve on their own, but under our watchful eye.
For the past few years, as part of Imbue, I've worked towards a vision of software and AI agents focused on individual human users--and their values1. We could see that increasingly powerful technologies would play a growing role in shaping our lives. Still, it wasn't clear how to operationalize that into something that increased individual agency and collective power over our systems and tools.
Then, one day about a year ago, I had a vision of the future of software creation.
In this future, people wake up, grab a cup of coffee, and check in on what has happened in their "software garden" overnight.
They make small adjustments--less of this, more of that, let's try something new over here--and then get on with their day.
In this new world, software is grown, not constructed.
In contrast, most software today is constructed by professional software engineers. While it's technically possible for software to do anything someone can imagine, any dreamer must rely on a software developer to turn that idea into reality. This leads to dynamics where software must serve a huge customer base to be worth building, forcing software applications towards the lowest common denominator. Software is built and sold to you; it's not grown, and users are at the whims of software creators to listen to their feedback or fix bugs.
AI coding agents let us flip that flawed paradigm on its head: now, everyone can create software. This creation becomes much more iterative, more personal, and tailored to the individual.
When you want a new piece of software, you provide the "seed" of the idea by telling an AI coding system what you want, and it... unfurls.
It starts by rolling out the idea. For example, let's say you're sick of seeing rage-bait in your news feed, and you want a program that will automatically filter it out. The AI coding agent can start working through the resulting questions:
What are the implications of this idea?
What are the primary challenges?
How should the system be architected?
Next, the agent starts creating specs and design documents, iterating on them, and developing an implementation plan. Finally, it begins writing code--just little prototypes,scripts and experiments at first, to learn and test the boundaries of the idea. As it gains confidence, it gains speed. It begins fleshing out the system, adding tests, etc., and rapidly growing and flowering into the full application that you originally developed. This happens without any real effort on your part, beyond providing the goal and your preferences and values. In just a short time, you have a whole new way of interacting with the news, free from toxic content.
Eventually, these AI coding agents can even coordinate the deployment of the software they create, making your new idea available to your friends or even the entire world. Your great ideas can now effortlessly bloom into software that, overnight, changes how the world interacts with their computers.
It doesn't stop there.
Our future AI coding systems will understand (and fix) production errors. They'll watch for GitHub issues reported by other users on the open-source repository, and even respond to and potentially fix them. They'll answer questions in the community Discord in real time or teach others how to use your new software. They might even do marketing activities--spreading the word about this new software, gathering feedback, and gaining inspiration for new features you might want to add.
Software written in this way is more alive and organic than today's software. It expands and evolves and reacts to its environment--perhaps adapting to the changing landscape of software by specializing in a niche, adapting to users' changing needs, or expanding its scope to increase the number of happy users.
Like the growth of any living thing, this process takes time and energy. But unlike software development today, this will be primarily electrical energy for computing rather than mental energy from humans.
In such a world, our role as software creators will not be as engineers, responsible for the low-level technical details. It may be more like that of a "gardener"--setting the right preconditions and tending to the projects via similar activities like:
"pruning" (removing dead or overly-complicated code, needless functionality, etc.)
"transplanting" (copying in common code from one project to another so it can co-evolve, combining multiple projects to achieve a larger purpose, etc.)
"harvesting" (publishing a successful prototype, actually using some "home-grown" scripts, etc.)
etc.
Or perhaps we may become more like "software bonsai artists." Bonsai is a skilled and ancient tradition of shaping growth to achieve specific aesthetic and practical ideals. Much like traditional bonsai artists, we may develop techniques that shape our software into something pleasing to us, both individually, and as a society.
Rather than creating heaps of new slopware, we could adapt software to our own personal preferences, workflows, and tastes by carefully pruning and guiding the growth of those systems, rather than abdicating responsibility and allowing them to grow into a messy tangle of branches and thorns. By approaching it like bonsai, and ensuring the proper growth of technology that embodies our values, we could create software that is more secure, more respectful of personal privacy, and more humane.
This world is within our grasp.
Our AI software engineering systems are improving at an incredible rate. Sure, today’s systems like OpenAI's Codex, Claude Code, or Sculptor are perhaps best thought of as having a horde of mediocre interns at your fingertips. But these interns are improving at an incredible rate--far faster than I've ever seen most human interns improve, and we've had some pretty amazing interns. If this rate of improvement continues (or even fails to slow significantly), we will probably have systems capable of creating and deploying software in a fully autonomous way.
We're already seeing glimmers of these changes.
Claude Code has grown to over $1 billion in annualized revenue within 6 months, and has entirely rearchitected how engineering teams work. There is an obvious path towards a world in which engineers are no longer involved in typing out lines of code, and this has taken less than a year.
The above is a visualization of the Cursor browser codebase from their experiment (generated using Gource). It's pretty ugly--lots of vendored code, tons of checked-in test binary blobs, etc. It could really use some pruning :)
Or look at Cursor's latest experiment in having a team of AI agents create a browser (one of the most sophisticated pieces of the modern software stack) from scratch in just a few weeks. Sure, the code is probably garbage and it barely runs, but the fact that it works at all, and that this was orchestrated by a single human engineer (without ever writing any code by hand) is a testament both to the technical possibility of this idea, and the need for approaching the creation with this new "bonsai" mindset. It's no longer hard to get AI systems to produce lots of running code--the challenge is now constraining that code to be something beautiful.
There are other challenges to overcome before everyone is fully empowered to become software gardeners and software bonsai artists. There are payment rails to consider, deployment infrastructure to create, and even whole new UI/UX patterns to explore.
But the wonderful and crazy thing about open source software is that it only takes one person solving each of those problems once for the solution to become freely available to everyone.
This will likely happen within the next two years, and when it does, we will see an explosion of personal software.
Instead of using Spotify, we may grow music listening software that contributes directly to artists. Instead of browsing Goodreads anonymously to find our next book, we could create software that helps us organize a book club with our friends. Instead of simply reading news online, we can make software that annotates misleading and biased claims, automatically cites trustworthy sources, and helps us develop more accurate beliefs about the world.
It's only a matter of time before these capabilities get good enough that, at least for some of us, it's more fulfilling to "grow" software than it is to "construct" it. There is a beauty and joy that comes from interacting with more complex, "living" systems that feel very different from the cold, calculating, logical world of today's software.
When that happens, we may find ourselves not choosing between engineering and agriculture, but discovering they were never truly separate. The gardener who understands a soil's chemistry is as rigorous as an architect with blueprints. The future belongs to those who plant seeds with intention, and then tend them with care.
I, for one, look forward to visiting our future software arboretums and conservatories.
Footnotes
We named the company Imbue because we want to help people imbue their values into their technology. ↩︎
The recent kerfuffle between Google and FFmpeg, where Google used AI to identify relatively meaningless security vulnerabilities and changed its policy to put time pressure on maintainers to fix them, is the latest in a long history of issues around ownership and compensation for open source projects. It also resurfaces some important questions:
Who should be responsible for fixing security vulnerabilities?
How do we want to use AI tools to identify security issues in open-source software?
Why should we expect a bunch of unpaid volunteer software maintainers to fix software for free on behalf of companies that have made trillions of dollars?
The dispute has grown heated, with FFmpeg developers publicly urging Google to either help fund maintenance or stop sending them so many issues to repair. They argue that a giant corporation with so many AI resources shouldn't dump unpaid work on a volunteer community.
Issues around large tech companies and Open Source software aren't new. For example, in 2015 Amazon started selling Elasticsearch as a service without asking Elastic (the company behind it). Elastic claimed that Amazon was confusing customers and stealing their code. Ultimately Elastic changed the software license to stop cloud companies from reselling it, which led to a whole debate around what counts as "open source" vs not.
Both of these are examples of the problems that arise when a company starts making money from software developed by others, but they're far from the only examples.
Companies, particularly large corporations like Google or Amazon, profit enormously from many open-source projects while contributing little towards their maintenance. This creates a classic collective action problem where everyone benefits from volunteer work, but no one has individual incentive to pay for it.
The conflict fundamentally comes down to a question of money, specifically: who should pay for the work of identifying (and fixing) the issues (including security vulnerabilities) that exist in open software?
Framed this way, the answer feels pretty obvious to me: if companies are making a lot of money from open source software, they should contribute some of those gains to actually fixing the software they rely on.
It’s not the code. it’s the culture
The core problem here is sociological rather than technical.
Open source culture was built on individual passion projects with manageable contribution levels, but this model breaks down when corporations scale up demands without proportional support. If companies increasingly use AI tools to generate massive amounts of bug reports and security findings, maintainers simply won’t have the bandwidth to keep up.
Expecting volunteer maintainers to address an avalanche of AI-generated issues or pull requests on behalf of Google and similar tech giants is clearly unreasonable. Maintainers shouldn't bear sole responsibility for resolving problems surfaced primarily through corporate AI systems rather than genuine community needs.
But this is about more than just security issues and bug fixes. There are bigger questions in play, including:
Who should pay to keep the software up-to-date as the broader software ecosystem evolves?
Who should pay for the direct (and indirect) costs of adding new features?
Who should be responsible for helping users, updating documentation, and the hundred other things that go into creating a healthy, thriving open source project?
The obvious answer to "who should pay for these costs" is "whoever is incurring the costs" and "whoever is making money from the software". That is, the companies that are building on top of any given open software project.
The licenses are actually quite clear about whose responsibility it is to fix bugs--it's literally the first sentence in all caps in the MIT License:
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
It's hard for me to read that as saying "Oh but don't worry we'll totally fix all the bugs for you". Rather, what it says very clearly, is that you, the user, are responsible for making this software usable for yourself. For Google to effectively bully open source projects by threatening to publicly release zero-day exploits, rather than going through the project's proper security channels and processes, is obviously hostile.
To its credit, Google does have its Bug Hunters bug bounty program. The company is also generally one of the better actors in the space, sponsoring a wide variety of open source software and programs (like Google's Summer of Code). In 2024, the company’s Open Source Programs Office provided $2 million in sponsorships and membership fees to more than 40 open source projects and organizations. But the fact that we're talking about Google being a "good actor" when they're making direct contributions of 0.0006% of their revenue towards open source is at least a little bit silly1.
We need more exploration and participation in this space. There are bug bounties, but very little money is transferred to the people who solve them. There are mechanisms for donating to open-source projects, but almost no companies make any contributions. There is a pledge for supporting Open Source software, but very few companies have signed on. There are some companies that allow some employees to work on open-source software, but the vast majority of software engineers are not paid to contribute to open-source projects.
This is a classic "free rider" or "collective action" problem. Companies benefit massively from the volunteers who create and maintain open-source software, yet have little incentive to contribute. As open-source adoption increases, so does the maintenance burden on volunteer maintainers. When overworked maintainers burn out and abandon projects, the entire ecosystem suffers.
Solving this collective action problem starts with acknowledging an uncomfortable truth: companies extracting value from open source have a responsibility to sustain it. Open-source software has become too vital to our infrastructure to rely on goodwill alone.
As software creation costs continue to collapse, millions of people are about to start creating software. We need infrastructure that makes the implicit norms explicit and enforceable, where commercial use requires negotiation, not just goodwill.
If you'd like to see something happen about this, maybe it's time we started talking about it. Share this article, leave a comment, or send me a note!
Yes, Google also has employees that work on Open Source projects, but it's complicated by the fact that there are business strategy reasons to release software as open source. Many of the "open source contributions" to their projects are more "code that Google was going to write anyway and which happens to be open" rather than an attempt to foster a healthy open source ecosystem. ↩︎
Perhaps surprisingly, the rise of powerful AI means that "free software" is actually one of the most important things anyone can work on today.
Allow me to explain.
As I've pointed out earlier, one of the core problems of our time is the increasing centralization of power: as we get increasingly powerful AI agents (and we will), it will really start to matter who controls those AI systems. If we're not careful about it, and we allow a small number of for-profit companies to control access to the power of AI agents, the results probably won't be pretty.
But what are "AI agents?" When you break it down, they're just software1
All we're really saying by "AI is becoming powerful" is "[a certain type of software] is becoming powerful".
Which is why a very specific type of "free software" matters so much: it's not that we care about Open Source versions of Photoshop or Windows, but that we need competitive, open versions of the specific type of software that matters in the future: AI agents (and their underlying models and infrastructure).
Ensuring that the best AI agents are open software (i.e., free or Open Source software) is pretty much the only way I've ever seen that has a chance of avoiding the dystopic AI futures that somanypeople are concerned about, and shifting the default outcome closer to the rosier, more optimistic ideas of what could be possible with AI.
At the core, it's a question of power: when AI agents are owned and controlled by a huge company, individuals become disempowered. They cannot change those agents, they cannot understand those agents, and critically, they cannot ensure that those agents are working towards their goals.
The importance of this point cannot be understated: if a company is running an AI agent for you, they will subvert the goals of that AI agent to benefit themselves.
It will simply be too tempting. Imagine that you run OpenAI. Some company offers you $1M to have ChatGPT suggest a particular toaster whenever people mention that they're thinking about buying a toaster. Many of your users are using ChatGPT for free! They expect to be advertised to! That's just the default business model for Google, so what harm is there in copying it?
And perhaps there's nothing wrong with advertising to users on the free plan. But it doesn't stop there: the long term game plan is to control not just product placements, but the ways in which agents do work for you. In the future, when you ask one of these commercial AI agents to create a report for you, or to write some code, or to do some travel research for you, they will be optimizing more for the company's goals than for yours. It's this mismatch, this conflict between "their goals" and "your goals" that is the fundamental problem--it's a classic example of what is known in economics as a "principal agent problem".
The problem with principal agent problems is that when there is a huge power asymmetry--like there is between an individual consumer and a $100B company--guess which goals end up getting prioritized?
If your goals conflict with theirs, they can even go as far as completely shutting off your access. This isn't a hypothetical concern--if you read the Terms of Service, you will see very clearly that you are not allowed to "compete with [their] offerings". This is a nonsensical term to include in products that are literally meant to be general intelligence--what business user would not be competing with one of these providers, in the long term? It seems crazy that AI providers would be able to cut off users who are competitive or unprofitable, but that's the world we live in now, and they certainly want to keep things that way.
AI companies will make all sorts of attempts to justify this crazy level of control. "It's safer," they'll claim, or they'll say "It's more efficient!", or "It's for security".
But these are fictions that are made up to justify centralization--they're not actually true. It's widely known open source system often have fewer bugs than proprietary systems (thanks in part to Linus's Law: "given enough eyeballs, all bugs are shallow"), and it's clearly safer to have transparency into agents than to treat them as a black box. And similarly, there's no fundamental efficiency reason why agents must be closed--it's merely more convenient (and profitable) for companies to keep them that way.
Even Anthropic, who produces a lot of valuable research on AI systems, hides the current agent chain of thought. Their documentation used to claim that this was for "safety" reasons, and while that justification has since been removed, the reason is (and always was) clearly driven by commercial interests: they don't want other companies copying their models.
Much of the hand-wringing about "AI safety" is precisely this type of capture and power centralization: by framing AI models as potential "existential risks" or "important for national security", these companies are positioning themselves to be the gatekeepers of what promises to be one of the most transformative technologies in all of human history.
When VCs and companies are pouring hundreds of billions of dollars into something, you have to ask yourself: are they all crazy, or do they actually see a plausible path to being able to exploit the world so much in the future that they'll be able to not only recoup that money, but make even more? The literal definition of investment is to spend money now in order to make a profit later, so you have to wonder: how are AI companies planning on making so much profit that they can justify spending upwards of a trillion dollars? The Stargate Project alone is estimated to be about $500B dollars. If we assume that represents half of the spend over the next decade, and they wanted to 2x their investment, they would need to make about as much money as is spent by everyone person during the entire year in Australia (as the 15th largest country by GDP, their GDP is about $2T). That's an insane amount of money.
It's simply not possible to make that money by taking a small fraction of the total spend--these companies are not looking to make a few percent, like an infrastructure or utility company (ex: power companies have around a 10% margin). These companies are going to be trying to make a 90% margin--they want to be selling you something for $10 that costs them $1. So when you ask an AI agent to do something in the future, it's probably going to cost you $10 for the work that OpenAI spent $1 to do. That's literally their plan: to make great margins, and expand to do a huge fraction of the world's knowledge work. And now you see why VCs and companies are so excited.
But it doesn't have to be this way.
We don't have to be stuck paying 10x above the fundamental cost of all knowledge work in the future.
If we can make free software and open alternatives to these closed AI systems, then these closed AI model providers won't have any real leverage or pricing power. If people are free to switch to their own open models at any time, or to run agents on whatever provider they want--including even their own local hardware--then these large companies will be forced to play the (appropriate) role of infrastructure. If they really do want to make "intelligence too cheap to meter", then we want them making money like utilities (10% margins)--not like software businesses (90% margins).
Thankfully, open models are already a surprisingly good alternative! Models like kimi k2 are extremely close to the best closed models on most benchmarks and leaderboards, despite being trained for a tiny fraction of the cost that went into training for the closed models. And open models have been getting better at a rate that exceeds even the closed models (which are themselves improving quite rapidly). Unlike even a year or two ago, when Meta's LLAMA models were pretty much the only game in town, there is now great competition at the model layer to provide the best open weight models, with companies like Moonshot AI, DeepSeek AI, and Reflection all hard at work to create the next best, most useful, open models and make them freely available to the world.
These open models are already having a powerful effect on the market--in just a short time, they've turned LLM inference from a place where companies had hoped to make healthy margins, to a place where even many of the closed AI companies are effectively forced to sell their models at a loss in order to compete. Because of the presence of open models, there's always an alternative of just buying your own hardware (or renting from a variety of cloud providers all in cutthroat competition with one another) and running an open model, which has strong downward pressure on the price of AI inference.
But the future of AI is about more than just open weight models and inference: we need viable open alternatives for the entire stack, all of the way from pre-training to the final systems for AI agents, and for usefully coordinating those agents.
This is why I'm focused on "free software" rather than focusing too narrowly on just, say, AI models or AI agents. Certainly, AI agents and their supporting infrastructure seem like one of the next most critical places where we need compelling open alternatives (which is why we've built Sculptor, and are planning to make its source available in the future). But it's more important that we create an entire, thriving ecosystem of open, free software for the entire lifecycle of training and deploying AI, lest some part of that chain become captured by a small number of for-profit companies.
One of the nice things about this effort is that it is gradual: it's not necessarily a binary outcome where either 100% of AI systems are closed or 100% of AI systems are open. Rather, each little library we make, each task we make more transparent, each new open source project contributes to making it easier to freely access AI technologies. Collectively, our efforts towards making open and free software eventually add up to shift the overall balance from closed to open.
If we can manage to keep free and open AI software components competitive with the closed alternatives for each part of the stack, or better yet, make them unarguably better (which I think is possible!), then I think we invite far better futures for all of us.
Rather than a world where these AI systems are black boxes, we can have a world where anyone can open them up and understand how they work (and improve them!)
Rather than a world where we are overcharged for access to the critical tools and technologies of the future, we can have a competitive market that provides useful AI tools efficiently and cheaply.
Rather than a world where money and power continually accumulates to a small number of the largest companies, we can have a world where anyone is free to run AI agents to build their own ideas and bring their own visions to life, and even make a living doing so.
Instead of a world with a small number of huge datacenters that pose national security and ecological risks, perhaps we can distribute the compute for AI to something that is owned and controlled by each individual, and which promotes a more stable geopolitical climate.
Instead of a world with a monoculture of models, we can have a diversity of local and personal models that are better suited to the individuals and communities that use them.
Sure, in these worlds, maybe some of these initial investors might not make the huge returns they were hoping for. But the rest of us will be far better off, and it's not our responsibility to guarantee their returns for such risky investments.
So let's ruthlessly copy and duplicate and commodify these closed AI systems. Let's share data, and collaborate on building open systems that benefit everyone in the world instead of creating a brittle world where our creativity and productivity are constrained to just whatever is boring and safe and profitable for the largest companies. Let's create an explosion of diverse ways of thinking and creating and building with software, where our future AI tools are directly under our own personal control, and where we can spend time working on the things that we care about without worrying about losing access to critical infrastructure because some company finds our work displeasing or unprofitable.
We can make good futures that have AI.
To do so, we simply need to make the software that is AI part of the public commons rather than something locked behind a private paywall.
So go forth, and make (AI-related) software free.
AI agents are literally just software, in the sense that they are instructions that run on a computer. Now, some of you might complain "oh but what about the weights!?" or "but that computer needs a GPU!!", but those are not particularly valid complaints -- I didn't see you complaining that something wasn't software when a small embedding model was downloaded, and nothing needs a GPU (it's just a lot faster with one). Yes, software that is largely a bunch of pre-trained weights is of a very different type than most software (because, for example, it is harder to understand and edit), but lots of software is hard to understand and edit -- that's just generally called "badly written software". The whole point of this article is that, hey, if AI agents are software, maybe we should do a good job writing that software, and that means we probably want it to be open. ↩︎
This is not to say that the other types of AI won't cause huge changes--they will.
The fundamental difference with AI agents is that they take the human completely out of the loop, and this changes everything.
Today's generative AI systems--chat bots, image and video generation, recommendations--are fundamentally about engaging with human end users. Humans can only consume so much content per day: no matter how good the AI is, you only have 24 hours in a day to watch videos, read chat bot messages, generate new images, etc. No matter how powerful and capable we make these generative systems and machine learning classifiers, there is ultimately only so much demand for their outputs because there are only so many people, and they only have so much attention to allocate. But AI agents are not limited by the global pool of human attention.
Instead, AI agents are only limited by the amount of "compute" (money) that we are willing to spend on them. And there are many places where the demand for knowledge work far outstrips the supply--literally every open job posting is an indication that some company wants to spend money on knowledge work, but is currently unable to do so.
In fact, estimating from open job postings would be a fairly gross under-estimate of how much pent up demand there is for more knowledge work: because the overhead to hiring and managing a new employee is so high, companies only post jobs that absolutely need to get done. Furthermore, the only jobs that get posted are those where it is profitable to hire someone. Given that skilled human labor is quite expensive, there are even more jobs that would be posted if only the cost were lower--and that's exactly what's about to happen as AI agents start to actually work.
Then the question is: what does the world look like when we have AI agents that really work?
What the world looks like when AI agents actually work
We actually already have an example of useful AI agents today: coding agents.
Over the past year, the capabilities of coding agents have improved dramatically from being occasionally useful for small, standalone scripts, to being able to create entire small projects and websites from scratch. Because I work in the space (we make our own platform for running coding agents, Sculptor), I've had a front row seat to this transformation, and the progress has been incredible. We're at the point today where our designer, who doesn't know how to program, used these tools to make a full clone of "Geometry Wars" that is honestly better than some of the sequels (we played both back-to-back last week). Revenues at companies like Cursor and Lovable have skyrocketed over the past year--some users spend >$1K per day on these tools, and there are reports of even crazier spending.
We can generalize a bit from coding agents in order to understand what to expect from other AI agents that we should expect to see soon. Coding agents work well because they are safe to use. If the agent makes a mistake and generates bad code (they often do), the downside is very low: you can just delete the code, and you've only lost the few cents that it cost to generate it.
We can likely expect agents to work in other domains where this property applies: if you can easily verify the output, or if most of the work goes into generating the right information rather than interacting with the world (which introduces opportunities for more serious errors), then agents are a particularly good fit in the short term. Other similar applications besides coding include things like creating research reports, presentations, low-stakes images, drafting emails, editing documents, and filtering through large amounts of information. Those types of activities account for a lot of knowledge work!
Coding agents are also a great example because they are not what people originally expected: the naive vision of coding agents was that you would have a "fully automated software engineer." This is not how it has played out. Rather, we have tools for human engineers that are getting increasingly capable of an ever-widening range of activities, and these tools are getting much more expensive.
This is why we haven't really seen major impacts on employment due to coding agents--yet. Because AI agents are only doing a part of the overall job of being a software engineer, companies cannot simply "hire" an AI system instead. Rather, companies are simply spending more money in order to make their existing employees more effective (which is arguably more productive for companies anyway, since having more productive engineers means fewer managers and lower overhead).
But that doesn't mean that AI agents won't have any impact on employment over the long run.
We're already starting to see companies change how they think about hiring. For example, the number of "front end developer" job openings has declined by almost 10% since last year, and some professions like "photographer" and "writer" have seen declines of almost 30% (source). It's not that there is less front end engineering work to do, but rather that today's coding agents are so good at such tasks that there's no longer as much need to have a dedicated employee for that role. Companies are simply restructuring the types of roles they are hiring to take advantage of these new capabilities.
What's somewhat worrying is that I can see a near future world where it actually will make sense for companies to "hire" AI agents instead of employees. Even just yesterday during lunch, one of my colleagues just left his laptop at his desk with the coding agent running while he played chess with another teammate. How long before the agent can not just run over a 30-minute lunch break in response to some instructions from an engineer, but can actually generate those instructions itself, and continue working around the clock? I think that day is a lot less distant than many people imagine.
The advantages of AI agents over human employees
Which bring us back to why AI agents matter so much more than all of the other types of AI put together: agents are what we call AI systems that do useful work, and they have structural advantages over human employees.
In particular, AI agents have seven main advantages over human employees:
1. The best agent can be copied infinitely.
Unlike humans, as soon as an improvement is made to one agent, it can be made available to all copies of that agent. This is part of why we see people switch between coding agents so frequently--when a new one comes out that is better, you might as well switch and use the improved version.
2. Agents can run 24/7
Unlike humans, agents can run around the clock.
They don't need to rest or sleep or eat. They can be constantly available to work, or respond to queries or changes that happen anywhere in the world.
3. Agents could theoretically think faster than humans
In theory, it might be possible to make agents that can not only run 24/7, but that can actually just think faster than their human counterparts.
Right now, while it's debatable whether agents can even be said to "think", it's not debatable that they can, for example, write code faster than humans (in terms of literal output speed). Over time, as that output gets higher quality, it could be extremely difficult to compete with a software engineering agent in terms of both quantity and quality of output in a given time window.
4. Agents have minimal management overhead
Unlike human employees, AI agents do not require human managers to discuss growth plans, performance reviews, or their feelings.
In fact, one of the major features for AI agents is precisely this lack of overhead--it's just really nice to be able to tell an AI agent to go write some code without worrying about its motivation or interests, since it has none.
Surprisingly, this is actually something that slows adoption as well--since human managers get some level of importance and status from having human reports, they're less likely to reduce the sizes of their own teams (even when that might be the economically rational thing to do).
5. Agents can be instantly scaled up and down
Unlike humans, agents can be almost immediately started and stopped, and they only need to be paid when they are actually working. This means that you could, as a business, suddenly start up 100 AI agents to get something done very quickly, then take them all offline (to stop paying).
The same cannot be done with humans--they get pretty annoyed when you stop paying them--which means that agents are a particularly good fit for cases where the amount of work to be done is highly variable.
6. Agents don't mind running in a nightmare surveillance prison
Unlike humans, agents don't mind having their every action watched in excruciating detail. This is perceived as beneficial for two reasons.
First, businesses often want to have metrics and visibility into work to understand how things are going.
Many businesses value legibility and transparency, even at the expense of actually getting more work done (for example, think of all of the time most people spend filling out work tracking reports).
Second, this seriously reduces risk for businesses. If you're watching an agent's every move, it's difficult for it to launder money, leave backdoors in software, etc. There may come a point where, from a security perspective, it's actually a best practice to not have human employees for this reason alone!
7. Agents are more tax efficient
This is a bit strange, but is worth understanding: money given to humans is subject to all sorts of taxes, including payroll tax, social security, healthcare, etc.
Money spent on agents, on the other hand, is treated fully as an expense--as a cost of goods. Actually, even worse than that, some money spent on agents can be counted as R&D expenses as well, which are even further tax-advantaged.
Thus, even if a human could produce the exact same amount of value as a human in the same amount of time, it'd be cheaper to pay the agent than to pay the human.
Where we go from here
Because agents have so many advantages over human employees, there is a huge incentive for businesses to get as much work done with agents as possible. This creates the pent-up demand for useful AI agents, and an enormous pressure for startups and other technology companies to develop reliable, useful AI agents as quickly as they can. Even if AI agents don't work very well today for any given task, it's a pretty risky proposition to bet that they won’t improve over time.
So while agents today are restricted to tasks like coding, where the outputs can be verified, and the agent doesn't need to really act in the world, we should expect to see the scope of knowledge work that agents can do expand over the next few years.
Slowly, we will start to see agents taking limited actions without any human supervision. We can even see the beginnings of this today with AI agents for low-stakes, easy-to-handle tasks like customer service, triaging support tickets, and answering emails. While humans still handle the more complex cases, their work can be recorded to serve as training data for the next version of the AI agents, which slowly become capable of taking on ever-more difficult tasks. The latest models have just surpassed human performance on GDPval (a suite of economically valuable knowledge work tasks)--how long before the majority of work can be done in a fully automated way?
It is this slow creep of capabilities that will happen over the next ~decade: AI agents will go from their nascent, bumbling, trivial state today, to a world where they are powering perhaps even most of the knowledge work being done in our civilization. Each new capability gained by AI agents is something that has forever left the realm of "economically useful work that requires a human to do"1--once one AI agent can do some work, you can make an almost unlimited number of AI agents capable of doing that same set of tasks.
That is why AI agents are ultimately the type of AI that matters the most: because agents have the potential to eventually perform the trillions of dollars of knowledge work that is done (for purely instrumental reasons) in our economies today.
There is a race to build systems that are capable enough to do so, and the final result of that dedicated effort over the next decade will be a world where white collar labor is completely transformed, or perhaps nearly absent (at least in the way we think of it today). No other type of AI system has anywhere near the same potential to radically re-shape society as AI agents that actually work.
Will these agents be working for you, or will they be maximizing profit for some company?
What kind of future are we building as the value of human mental labor approaches zero?
Even if this plays out over 20 or 30 years instead of 10 years, what kind of world are we leaving for our descendants?
What should we be doing today to prepare for (or prevent) this future?
These are questions that are worth engaging with--and sooner rather than later.
If you're interested, follow me on Substack--I'll be writing more about these (and related) topics over the next few weeks!
Just because humans are no longer required to do a task (from a purely utilitarian perspective, e.g., in order to get it done at all), that doesn't mean that they won't still be employed doing that thing. Think about furniture making--just because machines can make furniture doesn't mean that we don't have artisan furniture makers. They're just valued for different things. Even if an agent can do it, there may be higher demand for the human-made version because of the other things that it signals, bestows, and communicates. ↩︎
I'm willing to bet a lot of money that AI agents will work over the next decade.
Today's AI agents are where self-driving cars were 10 years ago. In 2015, self-driving cars could navigate a closed course flawlessly but would panic at an unexpected construction zone. Today's AI agents can write elegant code but stumble when asked "should we include this graph in the client deck?"
We're in the same transitional moment--and the path forward looks remarkably similar. Over the next few years we will start to see agents excel at an increasingly wide variety of tasks, and this will lead to drastic changes in our work and in our lives.
To understand why, we first need to examine how rapidly the underlying language models have advanced.
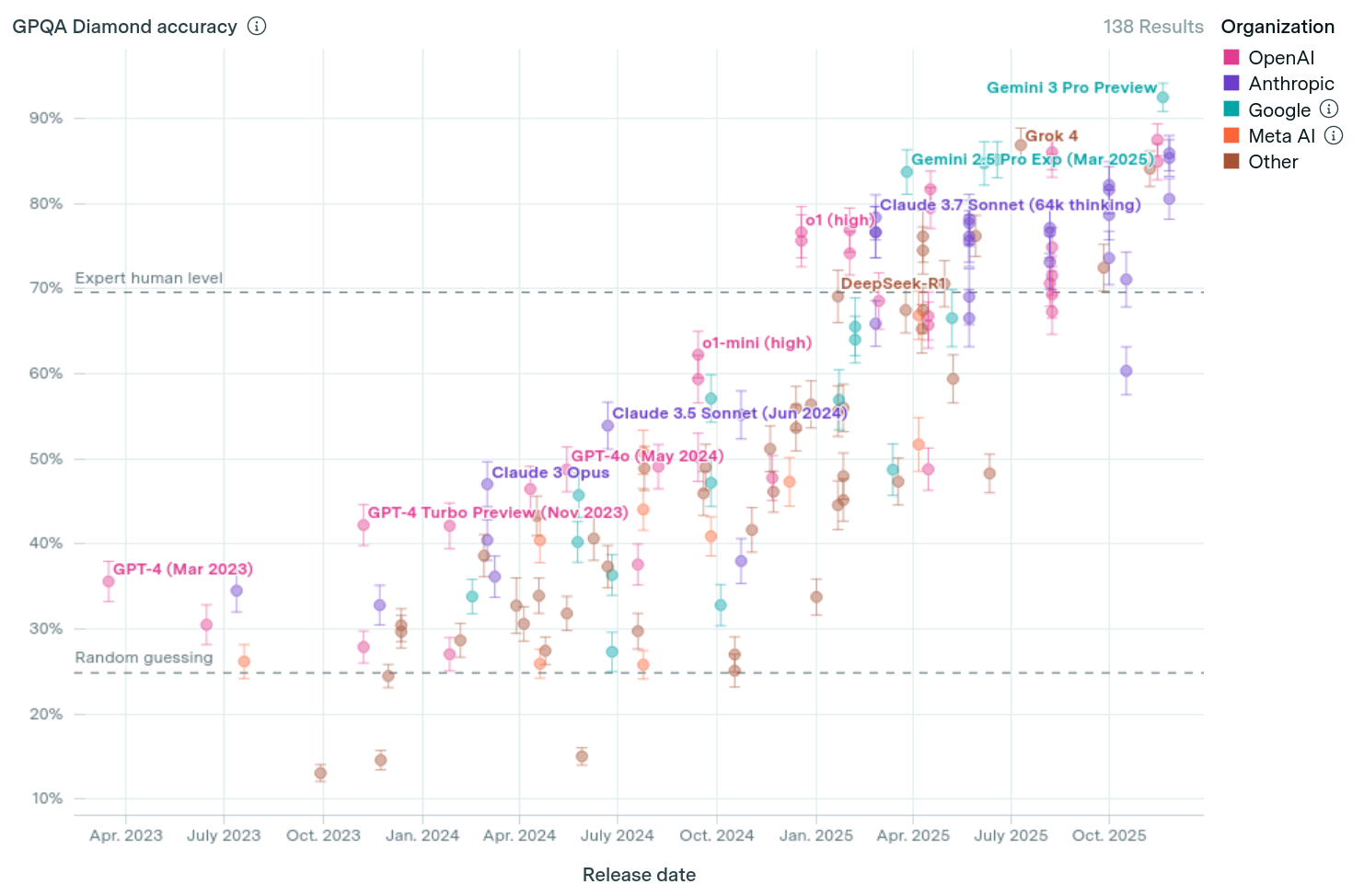
Below is a real example question from GPQA, a challenging dataset where human graduate students achieve ~70% accuracy. Today's best models are ~90% accurate:
Astronomers are studying a star with a 1.5 solar radius and 1.1 solar masses. When the star's surface is not covered by dark spots, its Teff is 6000K. However, when 40% of its surface is covered by spots, the overall photospheric effective temperature decreases to 5500K. In the stellar photosphere, when examining the ratio of the number of neutral atoms of Ti in two energetic levels (level 1 and level 2), astronomers have observed that this ratio decreases when the star has spots. What is the factor by which this ratio changes when the star does not have spots compared to when it has spots? Note that the transition between the energy levels under consideration corresponds to a wavelength of approximately 1448 Å. Assume that the stellar photosphere is in LTE.
A. ~2.9
B. ~1.1
C. ~4.5
D. ~7.8
I don't even know what that question is asking, and would have no idea where to get started, but we're at the point where models have far surpassed even graduate students with experience in the relevant field. And this progress has happened over just the past few years:
Sure, some of these model providers may have over-optimized their systems for these tasks, or overfit to the training (or even the test) data. But the trend on all other challenging datasets looks the same; absolute performance is similarly impressive; and at least the leading providers (like OpenAI and Anthropic) are very serious about their evaluations, as can be seen by how well their previous systems generalized on held out problems
If AI models can answer these difficult questions with a high accuracy, it seems like we really should be able to make models answer questions like "Should I email the customer about this?" and "Should we include this graph in the powerpoint presentation for client?"
Which is precisely what is needed for AI agents to actually work.
How language model capabilities enable AI agents
Language models answering graduate-level multiple choice questions are sort of like the self-driving cars of 2015 being able to outperform a human driver on a closed race track--impressive, but ultimately not that useful. And the delta between "great performance in a closed environment" and "actually useful in the real world" is caused by the same underlying factors that caused that disconnect for self-driving cars back then.
Ultimately, all knowledge work boils down to a series of decisions--questions of the form "what is the best thing to do next?" In theory, having large language models that are good at answering questions ought to enable powerful AI agents.
But today, AI agents don't really "work"--they're interesting and fairly useful in some small domains (like computer programming), but the vast majority of knowledge work is still done by people.
So why the disconnect?
The four missing pieces required for agents to "work"
I argue below that the disconnect is not fundamental (as some skeptics argue1), but rather that there are four practical missing pieces required before we see AI agents actually "work":
Exposing data to agentic AI systems
Codifying best practices
Developing new AI primitives
Building infrastructure to support large scale inference
These missing pieces are precisely the factors that enabled self-driving to work, and we will see significant progress for AI agents on each of these axes in the near future.
Each of these activities is being aggressively pursued by a wide range of companies, organizations, and people, and I believe we should expect to continue to see rapid improvement in each over at least the next few years. And if we make progress on each, AI agents seem likely to work far better than they do today.
1. Exposing data to agentic systems
In order to make self-driving cars really work, the cars needed to move from "car with cameras" to "car that knows every curb height and lane marking in its operating area." The breakthrough was less about better algorithms for control, and more about giving cars access to a richer understanding of their environments via access to more data (including HD mapping and sensor fusion), as well as much better understanding of that data.
A large part of why humans are still so much better than AI agents at many knowledge work tasks is simply that we have access to more data. We can answer the question "Should I send this to the client" not because we are fundamentally more clever, but because we've interacted with the client in person, we've gone back and forth in Slack messages with our colleagues, and we've overheard snippets of relevant in-person conversations and context. Many of the questions are not hard to answer when given access to the right information--it's just that all of that information is scattered throughout space and time and a thousand different internal and external systems.
If AI agents are to actually work well enough to make a meaningful impact on the world's economy, they will need access to the same data as their human business-person counterparts.
AI agents currently lack easy ways to acquire that data, but as more of that data becomes digital even the performance of today's systems might be sufficient for a fairly large set of the business-relevant tasks we do today.
Because of this, tons of people and companies are working aggressively on solving this problem. OpenAI, Anthropic, and Microsoft all have integrations with popular data sources (ex: Google Drive, your email, Notion, etc) in order to give their systems access to your business and personal data. Microsoft Copilot is built into the Windows operating system specifically because it can (at least in theory) have more access to data. Startups like Glean and others are scrambling to make internal corporate data searchable and more accessible to agents, and the whole reason for all of these RAG (retrieval augmented generation) startups and infrastructure libraries is that such techniques hold the promise of making more data accessible to AI.
Coding agents like Antigravity and Claude Code are being created by the big players not only because they're a good business, but because coding agents are yet another way of conveniently making more data accessible to future AI agents (e.g. by enabling the agent to write ad-hoc integrations and data access scripts itself)
While much of our data is scattered and hard to access now, I'm quite certain it will be a very different story in 10 years.
2. Codifying best practices
AI is improving incredibly quickly. The products you see today were developed on earlier models, and have not yet incorporated any of the research published within the past 6-12 months. There are virtually no best practices and no real body of knowledge for how best to design practical agentic systems.
It feels like almost every day that there are new, genuinely useful new techniques being developed by advanced users of coding agents. More complex earlier ideas (like MCP servers) are being replaced by simpler primitives that are easier to use (ex: see Anthropic's recent "Agent Skills" in Claude Code).
It takes both time, and real world experience (and failures) in order to develop these best practices. Much like in self-driving, where the successful companies realized early that simulation alone was insufficient; you needed millions of real-world miles to encounter the long tail of edge cases. Agents face the same challenge: we're still in the "accumulating miles" phase, figuring out which techniques work in which contexts. Every failed agent deployment is data. The best practices will emerge from deployment, not theory.
The process of creating best practices is fundamentally about discovering these real-world failure cases--and finding ways to increase reliability by preventing similar mistakes in the future. Today's language models have been optimized to do a "good enough" job for consumer use cases without driving the cost up too much. But as companies shift to agents doing real work, there will be increasing demand for accuracy and reliability, even if the cost ends up being higher.
And there already are a variety of fairly simple ways to increase model accuracy by simply paying more--it's just a matter of figuring out best practices about which techniques to apply when. For example, "ensembling" is a well-known technique in the traditional machine learning literature which allows one to incur higher costs in order to get better accuracy (basically, an "ensemble" of different models all answer the same question in order to have their errors "cancel out"). In fact, with questions where the answer can be objectively and deterministically evaluated, it's possible to simply sample even a single model multiple times--recent research has shown that doing so will continually increase the chance of finding the correct answer. As more samples are drawn, the chance of finding the right answer increases log-linearly with the number of samples, which is actually pretty good!
We've seen these techniques perform well in our own work as well: by using multiple models, by taking multiple samples, and by allowing AI agents more time to think and use tools, we've seen much better performance on a variety of tasks (everything from generating code to identifying bugs in existing code). Our product, Sculptor, takes advantage of these types of techniques in order to identify potential problems for users, and we're working on adding a native "sampling" mode to make it even easier to try out multiple coding agent models simultaneously on the same problem.
Over the next few years, we should expect to see far better performance in AI agents--even if the underlying models and capabilities remain exactly the same (which seems unlikely).
3. Developing new AI primitives
Self-driving benefited massively from the creation of new AI models like "transformers"--the models that also power today's language models and agents. First released in 2017, transformers enabled self-supervised learning about the visual world in a way that was extremely useful for self-driving cars. Originally just one small component in a larger, more traditionally engineered system, these and other new AI models have grown in scope and complexity to the point where today's self-driving software stack is largely new AI models that are trained "end-to-end".
Part of the reason why we should expect AI agents to work more broadly is that the underlying models and AI tools will continue to improve. Companies will continue scaling up their models, refining their data and techniques, and devising cleverer ways to set up the training methods for their systems.
But it's important to realize that AI research is not slowing down--if anything, it's accelerating.
The number of papers submitted to NeurIPS (the largest AI conference) each year has grown by over 10x over the past 10 years2--and there has been little (if any) drop in quality. Each year, we get new papers for more efficient models, distributed training, new types of memory, and other transformative new techniques that enable yet more powerful AI systems.
We're even starting to see the beginnings of fundamental scientific laws for "deep learning" (the technology that underlies modern AI, and which is still more black art than repeatable science and engineering). Such theoretical breakthroughs could, in the best case, enable far more efficient methods for training models (and in the worst case, would at least allow us to understand the natural limits of our current approaches).
These coming breakthroughs--both the theoretical, as well as the practical--will help dissolve the current barriers to AI agents actually working. Even if the skeptics are completely right, and the current paradigms are insufficient for "true" intelligence (whatever that means), such claims are unlikely to be true forever: new graduate students and researchers will be continuing to build on top of earlier work, and invent new ways of thinking about AI that could allow us to break through those limits.
In a sense, that's already what we have today--today's systems are not some simple, single algorithm, but a collection of tools, tricks, and hacks that we have collectively refined over the past few decades of research. Adding more tools to the toolbox will simply make it easier to make even more intelligent systems.
It's hard to predict the exact order in which various breakthroughs will appear, but it's a pretty safe bet that they will appear. There's simply too much money and talent flowing into the space for any other outcome to be particularly likely.
4. Building infrastructure to support large scale inference
One of the most under-appreciated reasons why self-driving cars work today is all of the infrastructure that was created behind-the-scenes. Waymo isn't just a self-driving car--it's a whole stack of fleet management infrastructure, maintenance operations warehouses, an app with geofenced deployment rollout, and even remote assistance for challenging situations. Both Waymo and Tesla invested heavily in infrastructure for data collection, model training, and simulation--literally thousands of people have invested years of their lives in these critical infrastructural tools, and it is this effort that is what has really enabled self-driving to work.
Similarly, much of what is stopping agents today is purely infrastructural: the necessary software and hardware is still in its infancy.
On the software side, besides infrastructure for accessing data (mentioned above), agents need a wide variety of boring, standard support for creating, debugging, monitoring, and deploying agents at scale. While it's easy to run a single agent, it's much more difficult to run millions of them in a way that is secure, repeatable, monitorable, and allows us to evaluate their performance. There are hundreds of new startups and software libraries popping up to deal with these challenges, and while many of them have grown incredibly quickly over the past year, there's still a lot left to build before AI agents are painless to create and deploy.
On the hardware side, the new infrastructure requirements are even larger. Multiple companies are each pouring more than $100B into AI data centers precisely because they are betting (in a huge way) that AI agents are going to really take off. It's a classic example of Jevon's Paradox, where increased efficiency can actually lead to increased demand: as the models get cheaper, the demand has skyrocketed. For example, OpenAI just released a report showing that usage of "reasoning tokens" has increased by 320x in the past year.
These sorts of infrastructural bets create a sort of self-fulfilling prophecy: if Microsoft and Google are wrong about the future demand for AI inference, and over-build datacenters, then the cost for using the resulting computer hardware will plummet, which will make it even more attractive to build AI agents to take advantage of that cheap compute. It seems very unwise to bet against a technology working when companies are pouring literally $100B+ into it (and into the supporting infrastructure)--even if they're wrong about the timing and lose a lot of money, they will create an abundance of cheap inference that will enable future AI agents.
Even once agents "work", deployment will take time
Even after the above barriers to useful AI agents are largely surpassed, and we have the ability to create extremely useful AI agents, the world will not be transformed overnight: there are plenty of barriers to adoption beyond just the difficulty of creating a working AI agent. Just as self-driving cars work today in sunny California (but not necessarily in a NY blizzard), there will necessarily be a slow expansion as capabilities improve.
But even if deployment of AI agents takes another decade, we're still talking about a radical transformation happening over a fairly short (~20 year) time scale. A world with reliable, functional AI agents that can outperform humans at most (if not all) knowledge work will likely be quite different from the one in which we live today.
It's worth recognizing just how much easier the problem of AI agents is relative to self-driving cars. Waymo has a much more difficult problem: it's controlling two tons of steel traveling at extremely high speed right next to other humans. Any mistake could be a matter of life and death, yet Waymo has managed to produce cars that have driven millions of miles at this point, and without causing a single fatal accident. There's no "undo" when you're driving; there's no ability to "pause" or "wait for the human to come check things out when you get confused". In contrast, using AI agents for knowledge work is a vastly easier problem.
Today's AI agents are where self-driving cars were 10 years ago. The DARPA grand challenge for self-driving had been won back in 2005, but in 2015 it still felt like we weren't really any closer to full self-driving in practice. Since then, billions of dollars of investment have taken us from cars that can barely manage to stay within a lane to a fully automated taxi service that can take you anywhere in the San Francisco Peninsula. It's amazing what a few billion dollars and thousands of smart people can do over a decade.
Much like self-driving over the past decade, today AI agents are poised to transition from something that works in "theory" to something that works "in practice".
Bit by bit, our tooling is improving, allowing us to make ever more powerful systems. It's not the "recursive self-improvement" / "hard take-off" scenarios of AI doomer nightmares, but rather the inexorable advance of technology and capitalism--ever better, ever faster, every more efficient systems for developing, optimizing, understanding, and running what is ultimately just various types of software. The fact that that software happens to be taking in every internal conversation at your company, or that it is now outputting think pieces and creating marketing content, doesn't change the fact that it is just software. It's just that it's getting much easier to make much more useful software.
In a sense, it's this "incrementalism" that is the strongest argument for why agents will ultimately work: as long as the world continues operating roughly as it does today, software never gets worse. Today's agents are the worst agents that will ever exist--AI agents can only improve over time3, and are doing so at an incredible rate. Agents are already incredibly useful in limited domains today (ex: certain coding tasks, finding security vulnerabilities, testing, summarizing, etc), and the set of tasks at which they excel can only really expand over time.
So whether it's this decade, or the next, I'm confident that we'll have useful AI agents in the near future.
Given that, now is probably a good time for us to start asking what that means for our jobs, our communities, and our future--which will be the topic of my next post! Follow me on Substack if you want to be notified.
There used to be a significant contingent of respectable AI researchers and scientists who believed that modern AI systems were missing fundamental pieces of what makes up human intelligence. Today, those numbers have dwindled to the point that practically no one believes that AI systems are fundamentally incapable of doing most cognitive work, but rather the disagreement now is more about precisely how much engineering work is left. This is evident in how experts have been repeatedly revising their estimates of "when will we get really powerful general AI systems" to be much shorter over the past decade or so, and we now have above-average performance even on the benchmarks that were explicitly created to demonstrate how much better humans are than AI systems↩︎
Because AI agents are software, any new version of that software that is worse can generally be "rolled back" to an earlier version that was better. This ability to roll back is not always accessible to end users (for example, you cannot use earlier models from OpenAI if they've been removed), but with open agents, this is always possible (which is another good reason to prefer open agents). ↩︎
It's looking increasingly likely that a few large companies could end up with control over most of our powerful future AI systems--which would be bad news for the rest of us.
Just imagine what such a future could look like:
Imagine a world where models have grown increasingly capable of performing complex cognitive tasks, gradually taking over more of the knowledge work that humans do, until eventually OpenAI/Google/Anthropic end up controlling over 90% of the intellectual labor in our civilization.
In this world, would these companies allow for paid product promotion? What about paying to promote ideas? Or paying to promote political candidates?
Would they allocate the bulk of our civilization's intellectual labor towards noble ends and prioritize science and the arts, or would they, as all corporations are legally required to1, prioritize profit--even if that means that we end up getting more AI slop instead of cures for cancer?
Even if the products and services were initially great, would they not slowly undergo a similar process of enshittification that we saw with web services as power was consolidated?
Even if these companies pledged to make the world a better place, should we trust their claims after they've gone back on almost everysinglethingtheypromised in the past?
Even if they actually created a program for Universal Basic Income, how likely would it be that those payments would conveniently be just enough for our yearly ChatGPT Plus subscriptions, which also just happened to be required to exist in this brave new world?
It's also curious to note that basically the only people in the world who are advocating for creating powerful, centralized AI systems are the people who stand to financially benefit from such an arrangement--I don't see any academics, non-profits, activists, labor unions, or regular people who are crying out for $500B+ worth of data centers to be created in order to make the world a better place.
For the rest of us, who are very likely to lose our jobs to automation if these systems actually work as well as promised, such centralized AI systems represent the concrete methods by which we will be permanently disempowered. As AI capabilities increase, the value of human labor (both mental and, with robotics, physical) will necessarily shrink. Put simply: if AI systems are as powerful and capable as promised, the rest of us will no longer be able to make money by working.
Critically, no one at these AI companies has any good ideas for how to prevent the massive unemployment that would result from them succeeding at their mission to create truly capable AI systems.
And unfortunately for the rest of us, "hope that powerful AI is impossible" is increasingly looking like a really bad bet. AI capabilities have been advancing at an alarming rate, and they're showing no signs of stopping any time soon. As much as it might be nice for AI progress to "pause" while the world catches up, causing technological development to pause currently seems about as hard as stopping the sun from rising each day2.
Past technological revolutions have created whole new classes of jobs and some argue that we’ll adapt just like before. But unfortunately, this time really is different: if we have computers with general purpose intelligence, then (almost by definition) that means we'll be able to create software systems to do those new jobs, too--and likely do so faster than we could ever possibly retrain humans to do the same.
Such a world could be quite demoralizing. Imagine being rejected from every job for which you apply, or being unable to retrain for a new job because those jobs are gone before you can even finish training, or machines that are even better than us at coming up with new business ideas (and better at executing those ideas), and we are left with literally no ways to make a living wage.
If the world continues on its default trajectory, it seems likely that most of us will end up disempowered and depressed, unable to meaningfully affect the world or the future.
What we can do about it
It's not too late to change our fate.
Remember: it's the combination of powerful AI and centralization that leads to these dystopic futures. Rather than trying to stop or slow technological change, we can focus on changing the degree to which the resulting power is centralized--and thus who benefits from these technologies.
You don't have to access AI only after accepting an onerous Terms of Service agreement that prevents you from developing your own AI tools or competing with these large companies--we could collectively agree that such agreements are obviously monopolistic, and pass laws to actually make them illegal, or we could simply use open models, the most recent versions of which have actually exceeded the performance of all closed models!
AI agents don't have to be systems that are corrupted by the incentives of some large for-profit company that is selling you access--you can run open agents that are guaranteed to be fully aligned to your own interests, and which can be audited and inspected to ensure that they are never trying to manipulate or overcharge you.
The profits from creating and selling valuable products and services don't have to accrue to the base model or agent providers--you can be the direct beneficiary of the value created by your own work.
If, rather than a world where AI systems are centrally controlled, we create a world where powerful AI agents are under the direct control of each of us, we might be able to make these technologies benefit everyone, not just the people who can afford to construct massive datacenters and spend billions of dollars training their own AI systems. If we can make AI something that we own, something that runs locally on our own hardware, something that is fully aligned with our own interests, we will all have roughly equal access to these powerful new technologies, and will be able to use them not just to do work and make money for ourselves, but to collaborate and work together to make the world a better place.
It's actually just as easy to imagine a future world where, rather than us being subservient to centralized AI mainframes, AI is deployed more broadly on each of our devices. Much like the personal computing revolution, we can imagine a personal AI revolution that enables everyone to use these tools for whatever they want, whether it's making fun new games, or learning about new topics, or coordinating their efforts to better solve some of the huge collective action problems facing the world today.
Critically, decentralized access to powerful AI gives us the ability to use AI tools in order to compete directly with the providers of those tools, which becomes especially important as those companies start to make truly "general" agents.
The difference between these worlds is really just about control. It's about who controls AI: you, or the companies that want to profit off of you?
If we can make AI systems something that is directly under user control, these better futures are possible. If we can distribute the use and production of AI systems, we can prevent ourselves from being slowly disempowered in the future, and instead live in a world where all of us are free to explore and innovate and build towards a brighter future.
These better futures are what I spend my days working towards. If you're interested in helping out, there's plenty to do--everything from working directly on software to give users full control over AI agents, to related projects for making software, AI, and data more open, more accessible, and more aligned with human interests.
If you're interested in learning more, just follow me on Substack--I'll be posting more about these projects in the coming months.
There are some people who continue to advocate for "pausing" AI progress, but at least in my mind, it's not realistic, nor is it even a coherent idea. There are simply too many people working on too many disparate things. To try to pause AI is to try to pause capitalism. Market forces are what drive the pressure to continually optimize and automate and improve our digital systems to make them more efficient, more useful, and more profitable. Given existing incentives and power structures, that's not something that the world seems prepared to meaningfully "pause." ↩︎
This site is intended as a collection of thoughts about how we might, together, build the futures that we want.
While most of the content here will be my own original work, I also hope to someday inspire others to contribute their own visions of the future.
As such, my content here is intended not to advocate for any particular world view or appeal to some particular political party, but to spark conversation--to ask questions about what all of us do, and don't, want from our world.
While I intend to keep this site as apolitical as possible, I do value clear thinking and civil discourse.
I was raised in an era before the internet isolated and polarized us, where op-eds were written by concerned citizens and published by newspapers that still did investigative journalism.
I believe that it is possible to have intelligent conversations about complex issues.
I love to learn ways in which I am wrong, so please feel free to reach out if you see something that is not right!
And if you do link to this site, please do so in a way that elevates our collective conversations.
It is often said that pictures are worth a thousand words.
Given how much there is to say about the serious issues facing us as a civilization today, and about the amazing opportunities in front of us, I will try to make my posts as visual as possible.
However, I am a terrible visual artist, so my images are generally created using Midjourney.
Where possible, I will try to cite the visual styles of the artists that I invoke in my prompts, but I'm still very much a novice in the world of art.
Please feel free to educate me about my mistakes!
My not-so-secret agenda with this site is to move the world towards a less cynical view of the present and the future.
I believe that most (but not all) people, when they are psychologically healthy, tend towards volunteering to help their fellow neighbors, towards benevolence, and towards selflessness, and towards the human virtues and values that inspire many of us.
I am deeply moved by scientific inquiry, curiousity, and the human spirit.
And I am inspired by the millions of people who wake up every day and try to, in their own way, make the world just a little bit better.